You have some kind of query - maybe it's written using Dataset API, maybe using Spark SQL. It reads from one or several Hive tables, or maybe Parquet files on S3 somewhere, and writes output to another table. It has some selects, joins, group-by's, and ends with some action to trigger the execution, for instance collect or count. This query is a very high-level description of the job Spark is doing. There's a long journey ahead, before executors would actually start doing their job. In this post we'll look into one of the transformations your query goes through - how it's turned from Logical Plan into Physical, and how to understand it.
While processing your query, Spark will go through multiple stages. Logical planning will happen first - at this point query will be parsed, analyzed and optimized, producing "Optimized Plan". It will go into "Physical planning" then, producing Executed plan, that will be later passed to DAG Scheduler, split into stages, then into tasks, and executed.
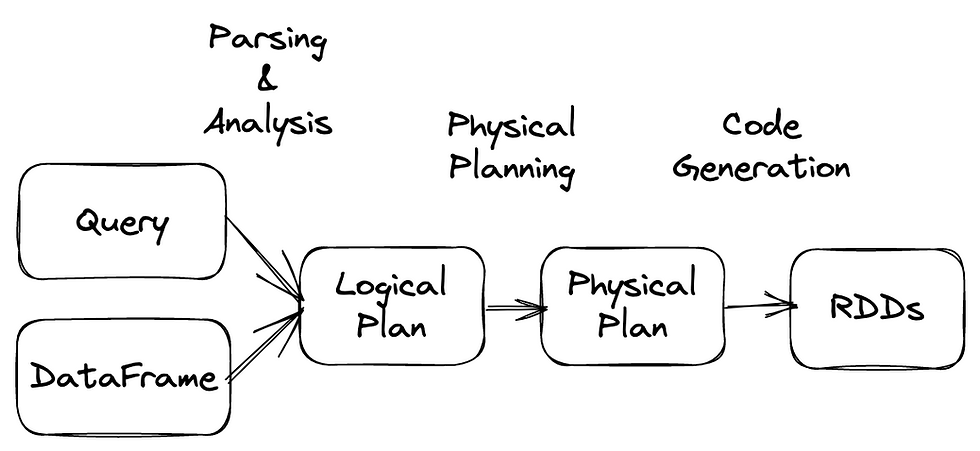
Logical plan is a high-level description of what needs to be done, but not how to do it. It has relational operators (Filter / Join) with respective expressions (column transformations, filter / join conditions)
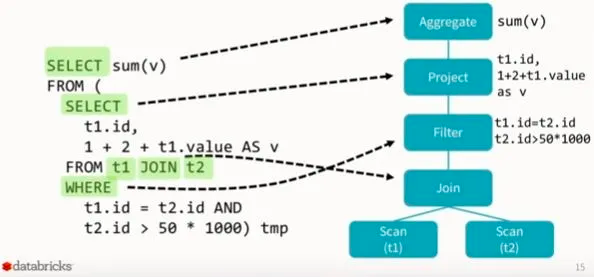
Physical Plan is a much more low-level description. It no longer uses DataFrames, but switches to RDDs instead, and has instructions on what exactly needs to be done, like sorting using specific algorithms etc. For instance, if Logical Plan has just Join node in it - Physical Plan would decide on specific strategy to do the join - for instance, BroadcastHashJoin or SortMergeJoin.

In SQL tab of Spark UI you can open some query and click on "Details" collapsable button - it contains different stages of Logical Plan, and Physical Plan. Another option is to call explain directly in your code - by default only Physical Plan would be shown, and Extended mode also shows different types of Logical Plan.
Physical plan operators
Now let's look at Physical plan, and into specific operators it may contain, in details:
FileScan
This operator appears in the plan when you're reading data from some external file, which is most often the case. This can be a csv or json file, but usually it will be some columnar format with metadata - probably parquet. Let's look at this example:

What you should pay attention to is PartitionFilters and PushedFilters.
PartitionFilters are easy to understand - if you're reading some file format that supports partitioning (for example, parquet or orc), and have a partition filter defined in your query (and if you don't - you really should) - only relevant partitions would be selected.
Additionally we should mention bucketing here. Bucketing is somewhat similar to Partitioning, buckets are also created from specific columns, but instead of strict "value creates separate partition", user specifies number of buckets, Spark hashes column values and puts same hashes into same buckets. If you have bucketed your data, and have a filter corresponding to bucketing column - there's a big chance Spark would be able to optimize your query by pushing down this filter, and reading only relevant files. At the same time, this optimization may lead to a problem later - even if you see stage split into 20 tasks (as input file had 20 buckets), only 1 bucket of data was read, and there was no actual parallelization - all work was done by one executor. You can control use of bucketing optimization using spark.sql.sources.bucketing.enabled parameter.
PushedFilters are a bit more interesting. As some file formats store metadata about how the data is actually stored inside files, Spark can use this metadata to optimize reading. For instance, if your file is sorted on id field - filter on this field can be pushed down to skip irrelevant row groups, even though data is not partitioned or bucketed by id.
Exchange
This operator represents shuffle - movement of data on the cluster. There are multiple ways of data exchange in Spark
HashPartitioning - usually will happen if you call a groupBy function, distint / dropDuplicates, in some cases of join, or when you call repartition(key).
RoundRobinPartitioning - this is usually caused by calling repartition(num_partitions).
RangePartitioning - caused by orderBy.
Aggregate
This operator will appear in Logical plan if you're calling operations like groupBy or distinct. In Physical Plan it will be turned into one of: HashAggregate, SortAggregate, ObjectHashAggregate.
This operator usually comes in pairs - you'll see `partial_sum`, then Exchange (not always), and then `finalmerge_sum`. First one is done on each executor separately, then data is shuffled, and final merge happens.
Join
SortMergeJoin - as you might've guessed from name, this operator would be added to the plan if you're joining two datasets. Often it will have Exchange and Sort happening before the actual Join.
BroadcastHashJoin - this operator represent another flavour of join, when one of the datasets is small enough to be broadcasted (sent to all executors) to join with a bigger dataset. Small dataset will have BroadcastExchange operator in it's plan, results of which go into BroadcastHashJoin.
Two versions of Physical Plan: Spark Plan and Executed Plan
Everything we've discussed before relates to Spark Plan. Before execution, Spark Physical Plan will be converted into Executed Plan, by applying some additional rules to it. One of such rules is EnsureRequirements.
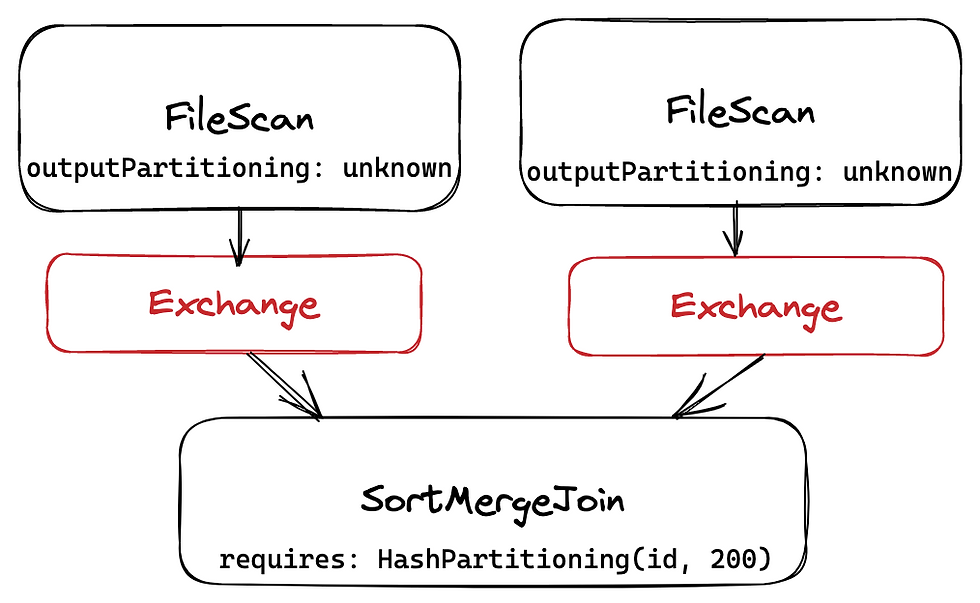
What are those Requirements? Each operator of Physical plan has several attributes:
outputPartitioning, outputOrdering, requiredChildDistribution, requiredChildOrdering.
If requirements of some child operators are not satisfied by outputs of parent operators, Spark will have to add Exchange or Sort operators to satisfy them.
For example, here we are reading some file with no metadata, Spark doesn't know anything about it's partitioning, and has to add Exchange operators to satisfy requirements of SortMergeJoin:
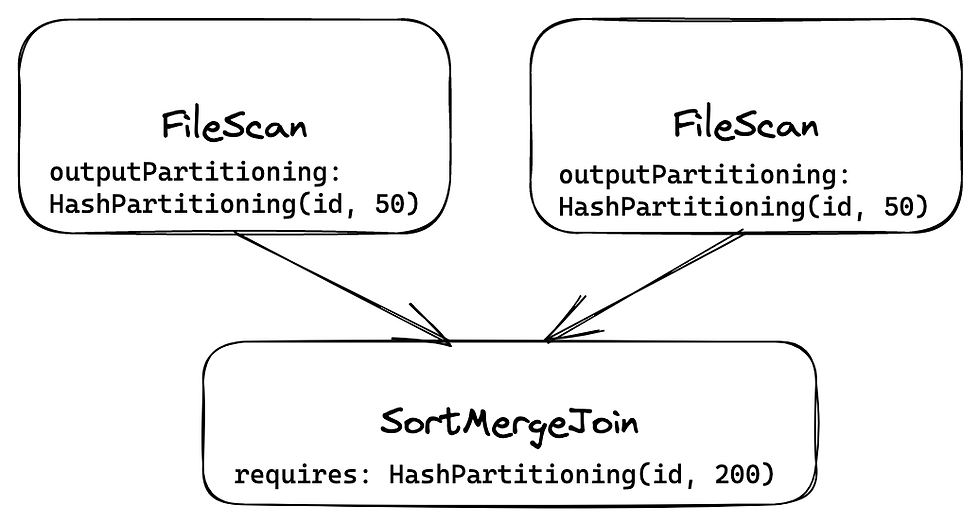
And in another case, we're reading bucketed file, FileScan operator can specify outputPartitioning of read operation, that satisfies requirements, so no Exchange is added.
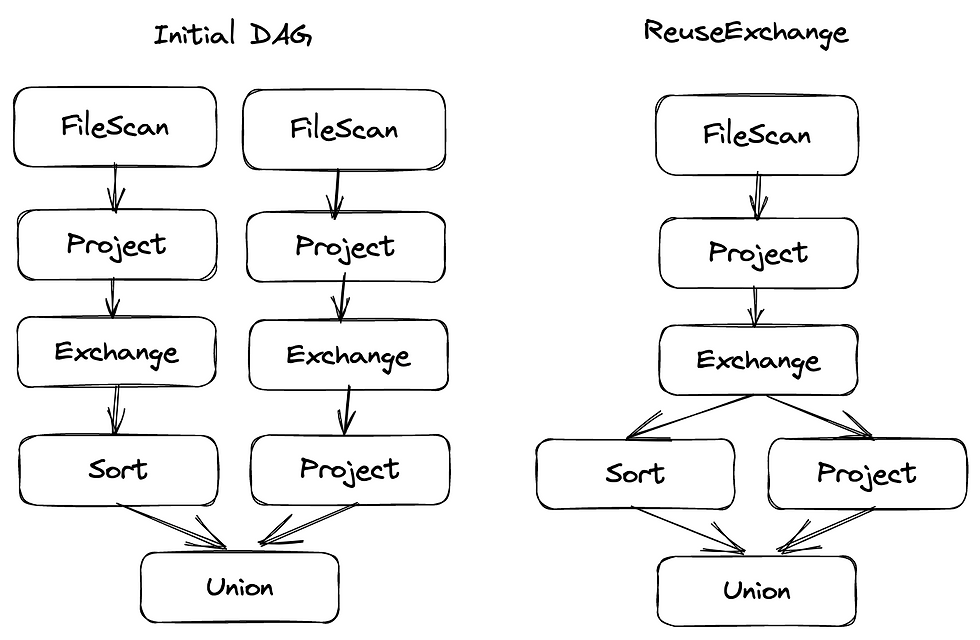
Another rule for generation of ExecutedPlan is ReuseExchange
When you have to shuffle data, results of such shuffle will be written to disk (you can notice Shuffle Write column in stage description in Spark UI). This means that if Spark notices that results of same computation is needed in another part of the DAG - it can preserve results of the shuffle, and reuse them. This feature can be disabled by setting spark.sql.exchange.reuse to False. Reusing results of shuffle should lead to lower IO and network usage, as data is read and exchanged only once.
Disclaimer:
A lot of information in this post comes from this excellent talk by David Vrba
All information here is based on Spark 2.4. Even though 3.0 is released already, many companies are still using 2.4 in prod, and the changes between versions weren't that dramatic, so most of the info will be applicable going forward.
Commenti